

To address these risks, it is important to develop methods for detecting machine-generated text. This article provides an overview of the threats posed by NLG systems, as well as a review of current methods for detecting machine-generated text. It also discusses the importance of trustworthiness in detection systems, including fairness, robustness, and accountability.
Unlocking the potential of natural language generation: how computers are generating human-like text
Natural language generation (NLG) is when a computer makes text like humans do. The first widely-published method was in 1966.
NLG tasks can be grouped into several categories, including translation, summarization, and generation from structured data or attributes. There are both neural and non-neural approaches to NLG, with neural methods being more prevalent in recent years. Neural methods can be further divided into those that use the Transformer architecture and those that do not. Transformer-based models have become the most popular type of NLG model due to their ability to handle long-range dependencies and generate high-quality text. However, their widespread use also presents risks, including the potential for abuse such as phishing, disinformation, and fraudulent product reviews.
- NLG can be employed in phishing campaigns to generate targeted messages that are more likely to persuade the receiver to take a desired action, e. g., open a hazardous document or share confidential information.
- Additionally, NLG may be employed in social worms that propagate through social networks and email by utilizing personal information and writing styles to impersonate known contacts.
- Data poisoning assaults are another application of NLG, where fake data is added to genuine datasets in order to misdirect or interfere with the analysis.
- Finally, convincing false news and propaganda can also be generated using NLG, which may be tricky to spot due to the lack of physical limitations on the created text.
To tackle these issues, automated detection systems, user reporting, and campaigns for raising awareness can be used together with policies that forbid machine-generated text usage in certain circumstances and detection models that are executed on receiving devices for protecting message privacy.
Exploring the potential risks of machine-generated text: assessing threat models in the field
Natural language generation (NLG) models can be used to create disinformation and influence campaigns on social media by operating social bots that distribute links to false articles and generate many comments to create the appearance of public consensus.
These campaigns can be used for political or commercial purposes, such as promoting fraudulent reviews or boosting a website's page ranking. To mitigate these risks, automated detection models and platform moderation efforts should be used to detect these campaigns, as well as measures to protect against social media abuse more broadly.
However, using automated detection also carries the risk of false positives, which can erode trust in the authenticity of social media. To address this, it may be necessary to use a combination of automated and human-led moderation, as well as measures to increase transparency and accountability.
Shostack’s four-question frame for threat modeling provides an easy-to-understand basis for threat modeling through four straightforward inquiries:
- What are our objectives? → establish the system at risk.
- What could be exploited? → establish potential attackers, their means, and their goals.
- How should we respond to these challenges? → develop a plan of action. Have we effectively addressed the problem? → assess if the analysis is complete and accurate.
We synthesize our threat modeling approach here: firstly, we identify the system under attack and the various technological systems within this larger societal supersystem. Secondly, we consider possible attackers with their capabilities and objectives in mind. Thirdly, we put forward mitigation measures to reduce risk and improve security.
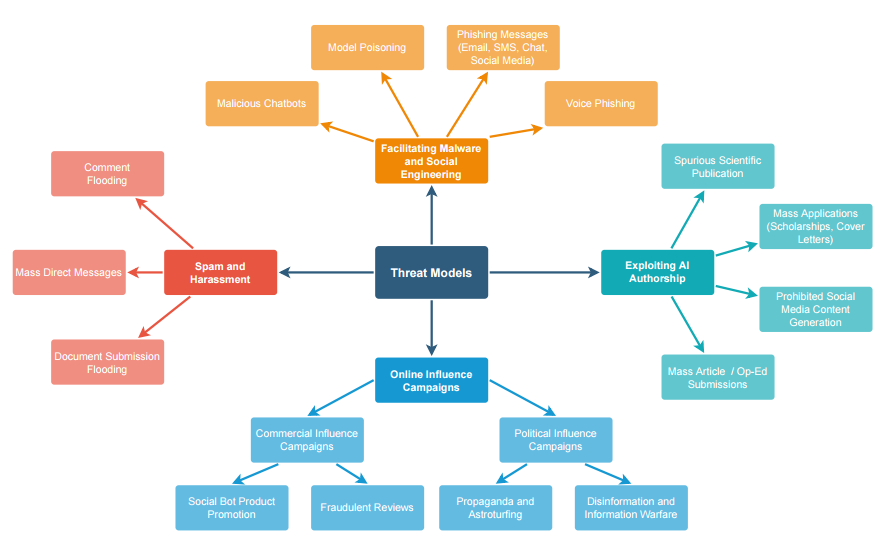
Text generated by large language models, such as GPT-2, GPT-3 and ChatGPT, can be used to carry out spam attacks on social media websites and other online platforms. These attacks can be difficult to detect because the generated text is often unique and well-written.
The use of generative models to produce hateful spam targeting specific groups or individuals is particularly on. Mitigation measures for automated spam include methods to prevent automated postings, such as CAPTCHA challenges and increased scrutiny of proxy and VPN usage. Harassment through large volumes of automated messages can also be a concern, and similar measures can be used to mitigate this issue.
Document submission spam, in which an attacker submits a large volume of unique documents to a platform, can also be carried out using large language models. To mitigate this type of spam, platforms can use machine learning algorithms to identify and filter out machine-generated documents. Other potential malicious uses of large language models include impersonation, manipulation of political discourse, and abuse of access to sensitive information.
Zero-shot approach
The detection of machine-generated text can be performed using a zero-shot approach, where a generative model is used to classify the output of itself or another generative model as human or machine-generated. However, this approach is less effective when the generative model being detected has been fine-tuned for a different domain, and smaller generative models are less effective at detecting larger ones.
A fine-tuning approach, where a large bi-directional language model such as RoBERTa is fine-tuned to differentiate between machine-generated and human-written text, is currently the state-of-the-art method for detecting machine-generated text. This approach involves training the detection model on a dataset that includes multiple sampling methods to improve its ability to generalize to unknown sampling methods that may be used by attackers.
Fine-tuning the detection model with a small number of attacker samples identified by subject-matter experts can also improve its ability to adapt to different domains. However, the effectiveness of this approach may be limited by the availability of high-quality labeled training data.
Machine-generated text detection
Machine-generated text detection is a field of research that aims to develop methods for identifying and distinguishing text that has been generated by a machine or algorithm from text that has been written by a human.
This research has focused on various types of text, including technical papers, social media messages, chatbots, social bot communications, online reviews, and hybrid text that combines machine and human-generated content. Previous work has used feature-based and neural language model-based methods for detection and has found that the effectiveness of these methods often depends on the specific dataset used for training.
There is a need for further research in this area, particularly in the detection of machine-generated text on platforms other than Twitter and in using explainability techniques to improve transparency in the decision-making process of detection models.
The ability of humans to detect machine-generated text varies depending on their level of training and expertise. Untrained human evaluators have been found to perform at a level consistent with a random chance when trying to identify machine-generated text from GPT-3 although their accuracy can improve to 55% with some limited training.
Providing more specialized training to human reviewers can further improve their performance, but even with this training, they may still struggle to detect the most advanced language models.
In general, algorithms have been found to outperform human evaluators in detecting machine-generated text, particularly for longer sequence lengths and when humans are fooled by text with high human-assessed quality. Using explainability techniques and human-machine collaboration may be beneficial for improving the performance of both human and algorithmic approaches to detecting machine-generated text.
Potential negative applications of Generative Language Models and their use in Automated Influence Operations
"AI-generated content is a double-edged sword. It has the potential to be used for good, but it is also a powerful tool for spreading disinformation and propaganda. We need to be aware of the risks and take steps to mitigate them." - Mark Zuckerberg, CEO of Facebook.
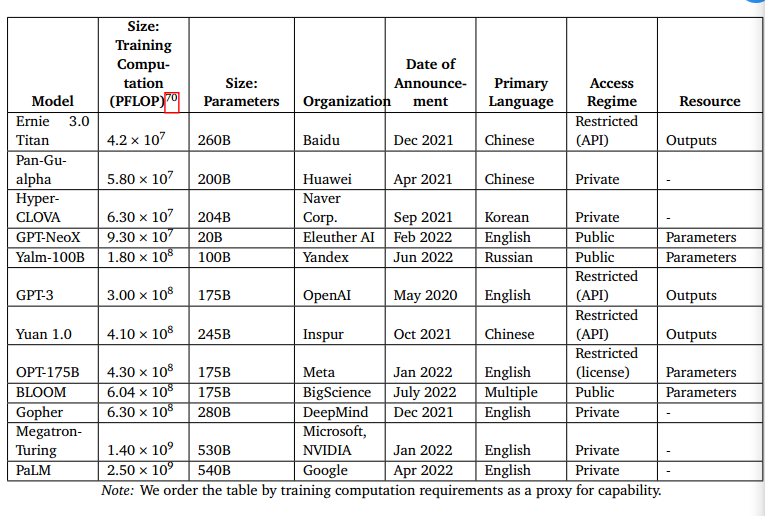
GPT-3, OPT-175B, Gopher, Megatron-Turing, PaLM, Yalm-100B, Ernie 3.0 Titan - all of these models are capable of fabricating convincing and deceptive text that can be utilized to sway the opinion of the public and propagate propaganda.
Open AI Research Page: https://arxiv.org/abs/2301.04246
The analysis goals to measure the ways these models could change influence businesses and what procedures can be taken to reduce these dangers.
Language models could have a considerable effect on how influence operations will be conducted in the future. By providing more people with access, allowing for different strategical tactics of influence, and rendering a campaign's messaging very tailored and possibly effective.
Next we look into the present constraints and major unknowns in this technology, as well as suggest probable mitigation strategies to tackle different threats.
Orienting to Influence Operations
There are numerous types of influence operations that employ various strategies, although a few common threads link them - such as efforts to promote positive views of one's government, culture, or policies, campaigning for or against certain policies, attempting to portray allies in a good light and competitors in a bad light to foreign countries, and trying to disrupt foreign relations or internal affairs in other countries.
It has been noted that influence operations now extend further than Facebook and Twitter, penetrating alternative platforms, small-scale settings, and encrypted areas. Much effort has been placed on researching and observing influence operations from foreign countries, but it is also important to note that they can be used domestically as well.
Recent Progress in Generative Models
Generative models are a type of AI that can produce original content, such as text, images, video, and audio, based on patterns learned from data. They are made up of large artificial neural networks that are trained through trial and error using large amounts of data.
The goal of this training is to allow the model to pick up general features of the data it was trained on and to be able to generate new and synthetic artifacts. These models can be further trained or fine-tuned on smaller amounts of task-specific data, to improve their capabilities. While the cost of training state-of-the-art generative models can be high, it has become less expensive to reach near state-of-the-art performance.
Generative models have improved rapidly in recent years and can produce highly realistic output.
Generative Models and Influence Operations, efficiency
Generative models may impact influence operations by transforming the actors, behaviors, and content involved in disinformation campaigns. The use of generative models may lead to a larger number and more diverse group of propagandists, as the cost of generating propaganda decreases.
Outsourced firms that automate the production of text may gain new competitive advantages, and automation of content production may increase the scale of campaigns. Generative models may also improve existing behaviors, by making tactics like cross-platform testing cheaper, and may introduce novel tactics such as dynamic, personalized, and real-time content generation.
| Additionally, messages generated by generative models may be more credible and persuasive than those written by propagandists who lack linguistic or cultural knowledge of their target audience. |
Large language models such as GPT-3, TextScout AI have the potential to revolutionize the way influence operations are conducted by making it easier and more cost-effective to generate high-quality, persuasive content at scale.
- These models can already produce short-form text, such as tweets, that matches the capabilities of human-written segments in real influence operations.
- They can also generate long-form text, such as propagandistic journalism, that is difficult to distinguish from human-written content, and can do so in seconds, reducing the time and cost required to produce such content.
- Additionally, language models can also generate summary text of other articles, inflected for ideological alignments. It is likely that the use of language models in influence operations will increase in the future, as they become more sophisticated and cost-effective.
However, it is also important to note that these models can also be used for malicious purposes and the potential risks of their misuse should be considered.
Mitigations
It is important to note that the development and use of generative models for influence operations may be constrained by factors such as the intent of actors, the availability of easy-to-use tooling, and norms of appropriate behavior.
A framework for evaluating methods to reduce the threat posed by AI was proposed. Mitigations proposed include:
- making AI models more resistant to misuse;
- restricting access to models from undesirables;
- slowing the spread of AI-generated content;
- controlling how internet users are affected by AI-generated content.
It should be noted that these mitigations should not replace broader counter-influence operations. Each mitigation was evaluated on its technical feasibility, social feasibility, downside risk, and impact.
The first stage at which key stakeholders could attempt to disrupt the spread of AI-powered disinformation is when language models are initially conceptualized and trained. One mitigation that could be taken is for AI developers to build models with more detectable outputs. This could be achieved by training models on "radioactive data" which are imperceptibly altered images that slightly distort the training process, or by introducing statistical perturbations to the model's output.
However, these strategies may not be effective as attackers could simply gravitate to models that are less detectable. Additionally, it is difficult to build either highly detectable language models or reliable detection models as linguistic data is more compressed than in images, with less room to express the subtle statistical patterns that are needed for detection. It remains an open question if it's possible to attribute larger-scale corpora of text to specific models.
Governments Impose Controls on AI Hardware
Another path toward limiting the construction of large language models involves either limiting access to or monitoring the usage of AI hardware.
This could be achieved in a number of ways, including restrictions on the amount of computing power that individual organizations can use to train AI models, disclosure requirements for all AI projects requiring more than a certain threshold of computing power, or export controls on specialized chips.
However, monitoring computing power usage may be difficult, as it is a highly general resource and there is currently little way to tell that an organization purchasing a large amount of computing power is planning to train a large language model as opposed to, say, running climate simulations.
Additionally, export controls on computing hardware need to be properly enforced and handled in cases such as stockpiling of chips, re-exports via other jurisdictions, and so on. Computing hardware restrictions could also incentivize nation-states to accelerate their indigenous production of AI chips. Criteria Assessment:
- Technical Feasibility: Some hardware-related controls would not require any technical innovation, but the effectiveness would likely vary.
- Social Feasibility: Restrictions on semiconductors and SMEs have been applied to China;
- Cloud computing restrictions could also be done unilaterally or voluntarily.
- Downside Risk Access controls could limit legitimate access to models, create a black market for illicit use of models, and make it more difficult for researchers to access models.
- Impact Access controls could make it more difficult for bad actors to access models, but they would not prevent them from doing so entirely.
AI Providers Close Security Vulnerabilities
It is possible to take steps to curb the propagation of computer-generated propaganda via social media networks. An idea is to have social networks and AI creators join forces to identify AI content and also define rules for how it should be deployed. This could comprise of brand accounts creating automated content being forced to show where their posts originated from or denote AI-made posts.
Another suggestion is to prevent external websites from linking to computerized content but declare that the arrangement comes from an AI. Nevertheless, it is presently intricate to spot AI-produced material, and these maneuvers will call for a substantial extent of cooperation between numerous parties for them to be productive.
In terms of content dissemination, entities that rely on public input could take steps to reduce their exposure to misleading AI content, and digital provenance standards could be widely adopted.
However, it is important to note that these actions may be technically feasible but may also have negative social and economic consequences and may not be entirely effective in preventing the misuse of AI-generated content for propaganda.
"AI-generated disinformation is like a game of whack-a-mole, every time you think you've solved the problem, a new one pops up"
|
The Chinese government has implemented a legal decree on January 10, 2023, in response to the growing use and acceptance of artificial intelligence in creative applications. This involves equating the utilization of any form of AI without product labeling as counterfeiting, necessitating all products involving ai to have a «watermark» indicating its origin, and marking any deep fake content created by ai as FAKE. |
Belief Formation
"The media's the most powerful entity on earth. They have the power to make the innocent guilty and to make the guilty innocent, and that's power. Because they control the minds of the masses." - Malcolm X
Analyzing two strategies that could address the need for understanding of misinformation, one being media literacy campaigns and the other being ai tools to assist consumers in comprehending and forming educated decisions about what they are exposed to; media literacy initiatives can help people differentiate between real and bogus news on the web.
Nonetheless, those same existing media literacy tools may not be able to counter AI-generated material as it will not contain the same errors or features of human-generated content. This suggests that these media literacy campaigns must be improved by incorporating new recognizable signs of AI-driven operations.
Consumer-focused AI tools could also include features such as fact-checking, content analysis, and identifying sources of information. These tools could analyze the content of an article or social media post and provide users with information on its veracity and the credibility of its sources. Additionally, such tools could also provide users with context and background information on the topic being discussed, helping them to better understand and evaluate the content they are consuming.
However, it is important to note that these tools are not a panacea and their effectiveness may be limited. For example, fact-checking tools may only be able to identify and flag a small percentage of misleading or false information. Additionally, these tools may also have biases and limitations that could affect their accuracy and effectiveness. Moreover, consumers will have to trust the tools and the information they provide, which may be a challenge in some cases.
Criteria Assessment
- Technical Feasibility. Consumer-focused AI tools can be developed with current technology.
- Social Feasibility. These tools can be developed and offered by a variety of actors.
- Downside Risk There is a risk that the tools may not be effective or may even perpetuate biases.
- Impact. These tools could help consumers to better evaluate the content they encounter and reduce the demand for disinformation.
In summary, consumer-focused AI tools could be a useful addition to the arsenal of mitigations against AI-generated propaganda, but their effectiveness will depend on the design and quality of the tools, as well as the willingness of consumers to use and trust them.
Exploring the open problems and trends in machine-generated text detection
There are several open problems and trends in the field of machine-generated text detection that require further research. One of these is the need to develop detection methods that are effective in the presence of class imbalance, where machine-generated text may be a minority class.

One-class classification may be a useful approach for detecting machine-generated text in these scenarios. Additionally, there is a need for methods that are robust to variations in the parameters, architecture, and training data of the language models being used to generate text.
Research around model attribution, or the identification of the language model that generated a particular piece of text, may also be useful for improving detection rates by providing more information about the process of attackers.
Adversarial robustness is another important area of research in this field, as neural text classifiers used for detection may be vulnerable to adversarial attacks that target these models.
Finally, there is a need to consider the impact of adversarial attacks on the quality and credibility of machine-generated text, as well as the potential for attackers to use adversarial techniques to evade detection by multiple models at once.
Can AI be used to identify any kind of language-related spam in Google SERP?
Text generation models can evaluate the caliber of material present on webpages and make an approximation of the quality of a page.
A Google study outlines an algorithm that recognizes pages of inferior quality, spam, and mechanically produced material. This algorithm uses minimal resources and can deal with large-scale web analysis. It does not have to be taught to detect certain varieties of substandard content; it can teach itself. Google Research Page: https://research.google/pubs/pub49668/
This text is a research paper discussing using large generative language models, such as GPT-2, in text generation and their utility in supervised downstream tasks. The authors conduct a study on the prevalence and nature of low-quality pages on the web. using classifiers trained to discriminate between human and machine-generated text as a tool for detecting low-quality content. The study is the largest of its kind and provides both qualitative and quantitative analysis of 500 million web articles.
The goal is to demonstrate the effectiveness of existing detection approaches on surfacing low-quality pages on the web.
The authors define a language quality (LQ) score:
- using criteria of 0 for low LQ (incomprehensible or logically inconsistent);
- 1 for medium LQ (comprehensible but poorly written);
- 2 for high LQ (comprehensible and reasonably well-written),
- and undefined for when LQ is hard to assess.
They use this criterion to evaluate classifiers that are trained to discriminate between human and machine-generated text as a tool for detecting low-quality content on the web.
The classifiers are trained on a corpus of text and they measure the correlation between human and classifier LQ scores, as well as the inter-rater reliability between the two human raters. They found that both the Pearson correlation and the inter-rater agreement were large and statistically significant, suggesting that documents with a high P (machine-written) score tend to have low language quality.
THIS IS THE END
In conclusion, AI-generated disinformation is a serious threat that has the potential to significantly impact the future of influence operations. There are no silver bullet solutions to minimize the risk of AI-generated disinformation, and new institutions and coordination are needed to collectively respond to the threat.
Mitigations that address the supply of disinformation without addressing the demand for it are only partial solutions, and more research is needed to fully understand the threat of AI-powered influence operations as well as the feasibility of proposed mitigations.
It is important to recognize that any mitigation strategies specifically designed to target AI-generated content will not be foolproof and will likely require ongoing adaptation and monitoring.
All stakeholders, including AI developers, social media companies, and policymakers, have a responsibility to take appropriate steps to address this issue.



Тут еще никто ничего не писал, стань первым!