

Ethical considerations are discussed in connection to the exploitation of data, the encouragement of unethical behavior and waste of resources. The opinion is expressed that AI should be employed for supervision rather than to make ethical decisions and steps should be taken to make sure it is utilized in an ethical way, including transparency, regulations and setting guidelines.
Generalization in a bulleted-list
- Neural networks work by being supplied with thousands of examples and adjusting the strength of connections between neurons to optimize outcomes
- The use of AI and algorithms can harm people by perpetuating existing social inequalities and promoting bias
- Algorithms are vulnerable to historical and dataset bias, as well as categorization bias
- AI is being used in detention centers and by businesses to make important decisions and analyze data
- The use of AI raises ethical concerns and there is a concern that human ethics could be replaced by robotic morals
- The manufacturing of electronics for AI often involves conflict minerals and exploitation of workers
- To ensure AI is ethical, concrete steps such as developing transparent algorithms and establishing regulatory bodies need to be taken
- AI ethics seeks to view ai as a tool, not a conscience, and to be led by people in any transformation.
What is the purpose of neurons in a computer, and how does a neural network form its thoughts?
Starting off with the basics - in order to comprehend how this works, we must understand the concept of artificial intelligence (AI). AI is a technology which is capable of performing similar tasks to what the human brain can do. However, due to advances in technology, AI can now use machine learning, which allows the program to come up with the correct solution to what it is trying to do.
In order for the program to be able to complete this task, it is supplied with a vast amount of data, which is known as a dataset. A dataset is an organized set of examples. The program then investigates patterns among these examples autonomously. For example, if you want to teach the computer how to make sentences in English correctly, if you use traditional programming techniques, you have to explicitly state all the regulations: how words should be inflected and in what order they are supposed to go etc.
On the other hand, with machine learning technology, the machine looks after all these issues itself: by studying millions of sentences it will recognize language rules for itself — and learn how to construct correct English sentences. Deep learning makes use of Artificial Neural Networks that resemble the neurological structures of animals and humans. Artificial neurons act as mathematical functions, taking information and passing it on to other neurons. Each connection between these neurons has an associated strength or weight which can range from zero to one. If the strength is equal to one, then the signal passes through in its entirety and is consequently deemed a «yes». However, if the strength is zero, then no signal will be passed on — this is like a definite «no».
In addition, any value between zero and one will be accepted by AI systems as they are capable of recognizing nuances between «yes» and «no.» In order for a neural network to begin thinking, it is supplied with thousands of examples which it must reproduce. After that, the strength of connections between neurons is adjusted so that the outcomes are optimized and solutions have been attained with the assistance of the info stored in the database. Going back to teaching a computer to write correctly in English as an example: a neural network understands how milk should be spelt because more often than not, it was spelt correctly within its dataset. Every time it decides on which letter it should place after «m», it selects «i» instead of «e», due to its stronger signal between neurons.
Proceeding onwards. Artificial neurons exist in three kinds: input, hidden, and output. Every one has its own objective: the first accepts the original data which is inserted into the network, the second processes it, and lastly the third renders the conclusion. This is easy to comprehend with another example. Say a neural network must make a call on whether to provide a certain person with a loan. The input neurons are made up of qualifications by which the person is evaluated such as experience, wages and marital status. The output neurons are what presents the final verdict: to grant or deny credit.
Hidden neurons are situated between them making up multiple tiers at once. Basically, machine learning is the process of selecting a state in a neural network (i. e. The connections between neurons) that will best reproduce a particular pattern. In this case, it’s to find out people with a specific set of parameters who are able to repay loans. By testing many different sets of parameters and discarding those that do not work, the neural network can identify the most effective combination.
This training requires considerable computational power and massive input information for it to be able to detect subtle patterns and make accurate predictions — for instance, they are used in digital marketing where algorithms make recommendations based on how users behave on the website and their reactions to advertisements so as to help them find products they will appreciate.
What issues arise from the use of algorithms?
The idea that technology can be more impartial than humans is appealing, but it simply isn't true.
AI still only reproduces patterns that exist in the real world, and so it reflects and promotes existing social inequalities. Consequently, with the rise of AI, human ethics are being replaced by "drone ethics" where decisions are made automatically without explanation or awareness of their impact. This has led to AI systems firing people without providing any explanation.
| ↘︎ An example of housing discrimination in the United States demonstrates that non-white people struggle more than white people to rent or purchase a house, as well as to obtain mortgages. It has been assumed that if decisions were left to machines, the issue of racism would be eliminated. However, a study from 2022 revealed that Artificial Intelligence replicates the same racism already seen, suggesting that even with automation, white Americans have a higher chance of getting a loan than non-white Americans when all other factors are equal. |
 Mark Fisher, a British thinker and music critic, once said that it is now easier to visualize the end of the world than the end of capitalism. He argued that today's popular culture is focused on nostalgia with no potential for revolution. Fisher concluded that the current capitalist system is the only way of production, which dictates that culture must constantly recreate itself with no possibility of change.
Mark Fisher, a British thinker and music critic, once said that it is now easier to visualize the end of the world than the end of capitalism. He argued that today's popular culture is focused on nostalgia with no potential for revolution. Fisher concluded that the current capitalist system is the only way of production, which dictates that culture must constantly recreate itself with no possibility of change.
The integration of AI into social networks perfectly illustrates this viewpoint. We are entrusting AI to make important decisions on our behalf and thus, we are depriving ourselves of a chance for social transformation. Rather than looking for new ways to achieve justice, algorithms are just upholding the existing structure of society and making it worse.
AI is vulnerable to bias and preconceived notions
Matteo Pasquinelli, a philosopher and media theorist, recognizes three kinds of prejudices. To begin with, historical bias, where algorithms repeat hardships that have always been present in society, similar to prejudice towards housing in the USA. Other sorts of prejudices, however, exist as well.
The second issue is the issue of the initial dataset (dataset bias). This dataset is the one that defines the behavior of an artificial neural network, and it is compiled by humans. To take an example, for an AI to be able to categorize images efficiently, it requires an enormous database which includes pictures that are preexisting labeled in some way - otherwise the algorithm won't be able to learn. Still, any form of initial categorization that is created by humans cannot be completely impartial by nature. As AI researcher Kate Crawford puts it, making a categorization is an act of control.
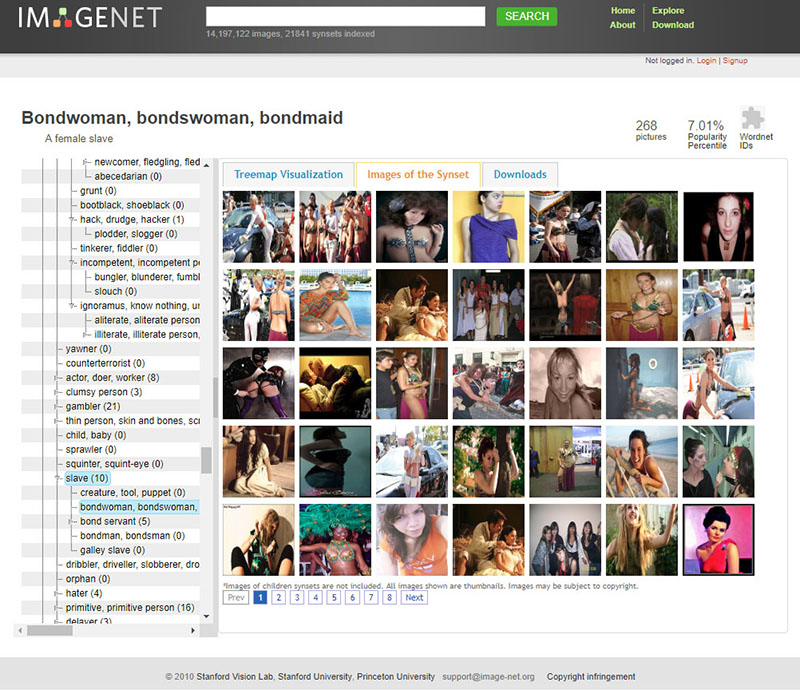
| ↘︎ Algorithms that interpret images bolster this argument. In the past, they were largely trained using ImageNet, which is an extensive inventory of photos that are split into various groups. For example, the "Adult Body" class is comprised only of the subgroups "Adult Male Body" and "Adult Female Body". That is, categorization implies that gender is limited to two possibilities. Consequently, bodies that are not part of the binary are overlooked by this sort of classification - and thus are overlooked by the algorithms that have been trained on it. |
Thirdly, machine learning and AI can produce distorted outcomes due to algorithmic favoritism. In essence, AI necessitates the formation of a comprehensive statistical model from copious amounts of data that can answer certain queries. For instance, is there a canine in this photo? Or, is it predicted to rain the following day? To put it in other terms, AI creates a form of the raw data, though it is impossible for the rendition to be totally comprehensive.
| ↘︎ In order to comprehend the degree of compression (and thus distortion) ai performs on data, we can compare model size and dataset it is based on. For instance, the inception v3 neural network which is applied in image recognition requires only 88 megabytes while the imagenet dataset it was trained with comes to 150 gigabytes — 1705 times bigger. Companies are even more focused on widening this difference. As philosopher matteo pasquinelli claims, they strive for a situation where ai will be given as much data as possible to ensure accurate predictions while its model should remain «light» so that it would consume as few computer resources as possible. This means information must be compressed and this inevitably leads to losing some important nuances which further aggravates any existing historical or source data biases. This means that the more compressed a face recognition model is, the more likely it will misidentify people from groups poorly represented in the original dataset. |
There are no "safe" algorithms
AI is used both in business and governmental operations. For instance, machine learning is employed by social media platforms to allow users to identify their friends in photos, and by governing organizations to facilitate surveillance of citizens.
Since its origins, AI has been responding to military and law enforcement demands. Paul Edwards, an expert in science and technology, pointed out that the first advances in AI at U.S. universities, including MIT, were backed financially by the U.S. Department of Defense.
Personal data is used to train AI
Even if users do not authorize it, why is this necessary? As you are aware, machine learning requires a significant amount of data, and the more of it there is, the more effective the model will be. Therefore, data sets may use anything that developers can obtain, such as public user data.
| ↘︎ As an example, in 2019, IBM developed a database of faces for the purpose of training a neural network that was untouched by gender or race. This database consists of millions of photographed images accompanied by facial expressions, ages, and skin colors information. It was soon uncovered that the photos were taken from users on Flickr who had no knowledge of this and never gave their consent. While the dataset was available to the public domain, it's not always the case and users may not ever know when their personal data is being utilized. |
The issue isn’t just that our private information is taken without us knowing, which in itself is bad enough. The real difficulty is what it’s used for. In the past, media platforms such as television relied on viewers' attention to make money. But now, social networks monetize people’s details. For tech giants, individuals are just a point in a multi-dimensional neural network space. Data gathered with or without permission can detail someone in thousands of ways and then accurately forecast their actions — and of course, make money out of it. The unevenness of power between businesses and clients is apparent here: you can never be totally certain what data was logged — and what deductions were made by the algorithms.
People are visible to the algorithms, yet the algorithms (and those behind them) remain unseen by customers — as if an unseen hand is guiding their current and future experiences.
AI is changing the very notion of ethics
Neural networks have the capability to forecast how certain aspects of reality could vary in the future, which is why both businesses and governments are turning to them to make significant societal choices. In particular, neural networks are being used in detention centers in Australia to decide whether a detainee is a menace or not. The model looks at various stats including a person's age, health condition, and behavior during and prior to detainment, and the outcome of the algorithm has an instant effect on the conditions of the individual's confinement - such as whether they will put handcuffs on him.
Businesses are also utilizing these networks to analyze their workers
Metrics are used to estimate the likelihood for an employee to leave their job in the future, such as the «turnover propensity index». Computers generate a turnover level for each employee through examining details like how many jobs they’ve had, what their position is, and their qualifications. Amazon has also adopted this method and utilizes artificial intelligence to terminate personnel if it believes they aren’t performing adequately. Another example is when XSolla, dismissed 150 staff members in 2022 on the advice of its algorithm — it worked out that these people weren’t productive enough.
 Managers often assume that metrics are more effective at forecasting an employee’s potential departure than a face-to-face conversation. Matteo Pasquinelli has another opinion, however. He remarks that ai is unable to form any causal associations between phenomena. Rather, correlation takes the place of causality; the statistical model just demonstrates how one element changes in connection with another. It is impossible to understand completely how the model works and what parameters and combinations of them influence the result and why. Networks containing thousands of artificial neurons are so complex that AI turns into a black box: its logic cannot be entirely explained in human terms. All this means that if an ai recommends you get fired from your job, you will never find out precisely what motivated it — all you will hear is something like «you seem to have lost interest in working for us based on certain patterns in your behavior.»
Managers often assume that metrics are more effective at forecasting an employee’s potential departure than a face-to-face conversation. Matteo Pasquinelli has another opinion, however. He remarks that ai is unable to form any causal associations between phenomena. Rather, correlation takes the place of causality; the statistical model just demonstrates how one element changes in connection with another. It is impossible to understand completely how the model works and what parameters and combinations of them influence the result and why. Networks containing thousands of artificial neurons are so complex that AI turns into a black box: its logic cannot be entirely explained in human terms. All this means that if an ai recommends you get fired from your job, you will never find out precisely what motivated it — all you will hear is something like «you seem to have lost interest in working for us based on certain patterns in your behavior.»
Even more importantly, the AI makes decisions proactively, based on a predisposition to a certain action, not on the outcome of that action. This is not to say that people never do this, but such actions often lead to real tragedies, as in Pakistan in 2011. Back then, members of the Loya Jirga Council of Elders met in the Datta Khel area to resolve a disagreement over chromite mining. From the air, their behavior resembled a gathering of al-Qaeda-linked insurgents, and U.S. drones struck the men. Two missiles killed between 19 and 30 people. It is unlikely that the deployment of AI was the basis for the decision to attack, although machine learning was still scarce at that time. Nevertheless, one can easily appreciate how machine ethics materialized in this circumstance: the superficial resemblance between the practices of innocents and those of rebels was sufficient to impose a death penalty.
 Since then, the military has embraced ai. Back in April 2017, the U.S. Department of Defense launched the maven initiative (literally «the expert»). Its purpose is to build a system that can identify people on images received from drones during counterterrorism operations in various countries (in 2018, u. s. Drones conducted operations in pakistan, yemen and somalia). This project accumulates a great deal of data and produces individual profiles of everyone spotted by a drone camera.
Since then, the military has embraced ai. Back in April 2017, the U.S. Department of Defense launched the maven initiative (literally «the expert»). Its purpose is to build a system that can identify people on images received from drones during counterterrorism operations in various countries (in 2018, u. s. Drones conducted operations in pakistan, yemen and somalia). This project accumulates a great deal of data and produces individual profiles of everyone spotted by a drone camera.
As ai researcher Kate Crawford noted, this is the perfect database for algorithms to decide whether someone should live or die. Beginning in the year 2020, project Maven has become a part of the advanced battle management system, an artificial intelligence which can process information from combat zones in real-time and suggest the most advantageous tactics for the military.
Dan mcquillan, an AI expert and philosopher, has noted that this type of «preventive justice» clashes with present concepts of justice. Most legal systems on earth are based upon the belief that someone is innocent until proven guilty. However algorithms have no such predisposition. As more states and organizations begin to trust ai to settle moral and social issues, there is a growing concern that human ethics could be corrupted — gradually supplanted by robotic morals.
Another problem with AI is that the algorithm is not just code
The complexity of the system with its AI components is merely the tip of the iceberg. There are numerous hidden issues that lurk beneath the surface such as depleting natural resources and modern-day slavery. According to media expert Jussi Parikka, digital media, and consequently AI, doesn’t just stem from interfaces, software code or even its hardware basis. It all starts with places where people work hard for a pittance.
Manufacturing electronics necessitates minerals extracted from politically unstable parts of the world which is why they’re referred to as conflict minerals. The Democratic Republic of Congo is one example with gold, tin, tungsten and tantalum being mined there. Several local mines are controlled by armed groups which implies that corporations who buy minerals from congo actually fund these armed conflicts as well as endorse exploitation of people since working conditions there nearly equate to slave labor: minors work in these sites without safety gear and full-time employees receive only two or three dollars for their labor.
| ↘︎ Since 2010, the American government has been striving to inhibit the utilization of minerals mined in battle-prone areas by requiring companies to account for their supply networks. The same regulation has been valid in the European Union since 2021, leading organizations such as Intel and Apple to attempt to make the asset of minerals unmistakable, yet it is troublesome. The supply chains are exceedingly intricate, with Intel alone relying upon an immense 16 thousand merchants. Subsequently, enterprises can look at the production lines where the raw materials are processed but not at the mines themselves. To conclude, it is liable that computerized devices like laptops, smartphones, and so on are still being made from minerals from questionable sources. |
 It’s not over yet — it takes a lot of energy to educate neural networks. This causes more and more co2 to be released into the atmosphere, since 37% of the world’s electricity is still generated by coal-fired power plants. In 2019, U.S. studies showed that teaching models to work with English (they are essential for translations) released around 300,000 kg of carbon dioxide into the air, equivalent to 125 trips from New York to Beijing and back.
It’s not over yet — it takes a lot of energy to educate neural networks. This causes more and more co2 to be released into the atmosphere, since 37% of the world’s electricity is still generated by coal-fired power plants. In 2019, U.S. studies showed that teaching models to work with English (they are essential for translations) released around 300,000 kg of carbon dioxide into the air, equivalent to 125 trips from New York to Beijing and back.
Finally, low-cost (and almost resembling slave labor) labor is utilized in another phase of AI production — the organization of databases which are used to train algorithms. It is important to remember that there are human beings behind automation, as researcher Lily Irani reminds us. For example, suppose machine learning requires a dataset which includes images and text descriptions. To generate this, developers rely on crowdsourcing websites such as Amazon Mechanical Turk, Clickworker or Yandex Toloka to enlist assistance. The workers on these platforms receive income for performing mundane jobs — like matching up a picture with the right text. The difficulty is that people working on crowdsourcing services are classified as independent contractors (including Yandex Toloka). That implies they get paid based on the outcomes of their work and are not subject to labor regulations (especially the provisions related to minimum wages).
As a result, sometimes crowdsourced employees make less than the lowest salary in their area even if they put in an entire day’s work. The public image of automation is that it displaces only mundane and uninspiring jobs, leaving creative ones to people. In fact, it is low-skilled and unprotected employees who suffer most from automation. Unfortunately, the attention given to their work is minimal — not only do they receive poor pay, but their efforts are also unseen. This holds true regardless of the fact that ai cannot exist without them in the same way as it cannot exist without programmers.
What steps can we take to ensure AI is ethical?
Can humans obstruct algorithms?
In 2018, Google personnel experienced an unexpected shock when they found out the company was working in private with the US Department of Defense. The image recognition technology created by Google was used as part of the maven project, which is a system for managing video from drones.
After learning of this collaboration, more than 3000 workers asked for it to end. As a result, superiors were pressured into giving in and ending their partnership with the military. Subsequently, Google set up ethical guidelines for AI engineers which banned the utilization of Google's developments in the armed forces sector. Furthermore, they decided that their ai should be unbiased and visible to users.

Ever since the emergence of various scandals and journalistic probes, states, enterprises and coders have had to contemplate how to render their algorithms more ethical. The concept of formulating regulations for AI use is not a fresh notion though; it was first advanced by science fiction author Isaac Asimov in 1942. In his story «Runaround» he outlined a set of conduct principles for robots known as the «three laws of robotics».
- A robot may not injure a human being or, through inaction, allow a human being to come to harm.
- A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
- A robot must protect its own existence as long as such protection does not conflict with the First or Second Laws
 The Zurich researchers found that Asimov's laws are not even rules, but rather the broadest principles for ensuring robots are used for good and not harm. Nonetheless, these principles do not provide any particular guidance as to how this «helpfulness» should be enacted — and in this regard, modern AI ethics manuals are similar.
The Zurich researchers found that Asimov's laws are not even rules, but rather the broadest principles for ensuring robots are used for good and not harm. Nonetheless, these principles do not provide any particular guidance as to how this «helpfulness» should be enacted — and in this regard, modern AI ethics manuals are similar.
In 2019, a survey was conducted of existing AI ethics documents that had been published primarily by governments, businesses, and universities. It is worth noting all of the guidelines were simply suggestions and not actual regulations.
The research revealed five commonly-followed recommendations among the 84 documents reviewed: Transparency — using ai must not be done in secrecy from the public. This includes things such as open source availability, making datasets available to anyone, or declaring the goals of the project publicly. Fairness and honesty — AI systems should not replicate any existing biases. No harm — algorithms must be created with safety for humans in mind and never used for malicious activities that could lead to discrimination or violence.
Responsibility and accountability - AI developers must be prepared for legal liability if their algorithms harm people.
Privacy - It is unacceptable to use users' data to train algorithms without their consent.
Joanna collected over 3000 stories of women’s experiences in the field of ai and created an open source platform for their sharing. This example shows that people are taking action to ensure that algorithms are not used to cause harm. To really implement these principles and make sure ai is used ethically, we need more than just general statements.
We need concrete steps that developers, companies, and governments can take to make sure they comply with the principles. This could include developing more transparent algorithms, creating detailed guidelines for how ai should be used, or even establishing regulatory bodies to monitor the use of ai.
In 2015, a young woman had to get hold of images of hands for her graphic design project. She googled «hand» and found that the output was entirely composed of white people’s hands. The search algorithms didn’t take into consideration those who were not white, as if they were an aberration. So Buray made up her mind to change this without the aid of Google developers. She made a website where she uploaded six photographs of non-white hands, together with a press release outlining the issue and its solution. The project went viral: Buzzfeed, the BBC, Al Jazeera and other major media outlets wrote about it and posted pictures from Buray's project, thus altering the search results in consequence. As a consequence, images did appear on the first page when searching for «hand» — and stayed there for quite some time.
The issue is that grassroots endeavors of opposition to algorithms just bring about sporadic outcomes. Project Buray briefly rectified web index results, yet it didn’t address the prejudicial rationale of web indexes all in all. To counteract this, the other option is to meddle with the rationale of the calculations. Columnists and researchers frequently talk about difficulties identified with artificial intelligence, which now and then bring about outrage, compelling organizations to react to them by adjusting their item code. Be that as it may, regardless of whether they do make changes, the code will in general stay covered up from people in general. What’s more, individuals are basically relied upon to accept that there has been an improvement in the calculation without seeing any proof.
The difficulty we face is that local initiatives of resistance to algorithms only create circumstantial effects. Project bury managed to alter search engine results for a time period but did not solve the discriminatory logic utilized by these search engines altogether. To battle this issue another way of countering is interfering with the logic behind these algorithms.
Observers and reporters are noting the potential issues artificial intelligence can cause, which could easily bring about scandals, and no matter what one says, one must react by adjusting the product code. Even if they take this approach, in most cases the code is kept far from public view. There is still a danger of contagion to consider.

The main challenge lies in how small-scale attempts at standing up against algorithms only yield patchy outcomes. For example project Bury was Moreover, AI issues can’t be solved solely by tweaking code elements or input data. It’s a complex system of effort, natural assets, and programming, concealed behind elegant user interfaces. Algorithms are as immoral as the fordist system of the capitalist economy is.
Dan mcquillan, a philosopher proposed a more strong-minded means to manipulate algorithms. In the areas where AI decisions have the greatest influence--law enforcement, education and social assistance--he suggests setting up people’s councils to control them. According to McQuillan, ai users aren’t subjects but targets — an information set without any voice. The incorporation of people’s councils to oversee ai would restore subjectivity back to individuals he believes. People whose lives hinge on algorithms would be able to dispute their decisions and adjust the source code architecture accordingly.
Dan McQuillan's vision is that people’s councils would be able to intervene at any stage of artificial intelligence development and implementation, from writing the code to using it for practical applications. For instance, such a council could decide that ai should not be used to determine which prisoners ought to be treated with more leniency or harsher punishment.
McQuillan believes that it is impossible for ai to consider all the differences between individuals and so people should be responsible for setting ethical standards and enforcing them through collective action.
The goal of AI ethics today is to demolish the illusion of Artificial Intelligence
There are too many people who have faith in the power of algorithms, believing they have human qualities. But it’s not possible to create a conscience that can be held responsible and make wise decisions from a computer program.
The philosopher Matteo Pasquinelli insists we view machine learning algorithms not as a form of intelligence, but instead as an instrument for monitoring. He calls them «nooscopes» (from the ancient Greek skop ein — «observe» and noos — «knowledge»). A no scope is like a telescope, yet it leads us through the world of data instead. Any tool for observing distorts reality in some way, lenses distort space and algorithms do the same thing. It is odd to give AI full authority to make important choices without thought.
To let it guess what’s ahead for us is just to remain captive to the past, along with its mistreatment and unfairness. Therefore, if any transformation is conceivable, it must be led by people.



Тут еще никто ничего не писал, стань первым!